Can Generative Video Models Help Pose Estimation?
Yes! We find that off-the-shelf generative video models can hallucinate plausible intermediate frames that provide useful context for pose estimators (e.g. DUSt3R), especially for images with little to no overlap.
Example Results
Method Overview
Given two images, our goal is to recover their relative camera pose. We introduce InterPose, which leverages off-the-shelf video models to generate the intermediate frames between the two images. By using these generated frames alongside the original image pair as input to a camera pose estimator, we provide additional context that can improve pose estimation compared to using only the two input images. A key challenge is that the generated videos may contain visual artifacts or implausible motion. Thus, we generate multiple videos which we score using a self-consistency metric to select the best video sample.
Video Generation for Pose Estimation: Benefits and Challenges
We propose to use a video model to hallucinate intermediate frames between two input images, effectively creating a dense visual transition, which significantly simplifies the problem of pose estimation. However, a key challenge persists: generated videos may contain visual inconsistencies, like morphing or shot cuts, which can degrade pose estimation performance. We show some examples of common failure modes of video models.
Selecting Visually Consistent Videos with a Self-consistency Score
One approach is to sample multiple such video interpolations, with the hope that one displays a plausible interpretation
of the scene that is 3D consistent.
However, how do we tell which video sample is a good one?
Consider a low-quality video that has rapid shot-cuts or inconsistent geometry, like Video 0. Selecting
different subsets of frames from that video would likely produce dramatically different pose estimations. We
operationalize this concept by measuring a video's self-consistency.
Experimental Results
We demonstrate that our approach generalizes among three state-of-the-art video models and show consistent improvements over the state-of-the-art DUSt3R on four diverse datasets encompassing indoor, outdoor, and object-centric scenes.
Quantitative Results
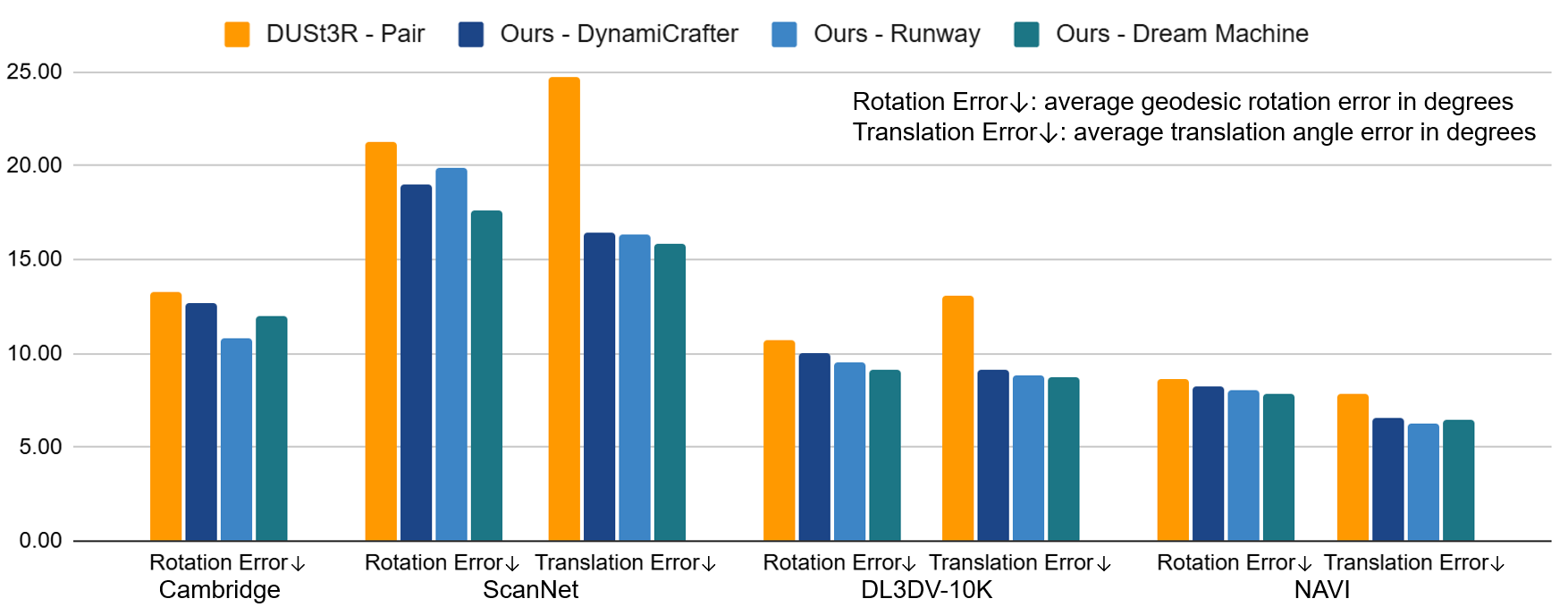
Our approach, integrating generative video models with DUSt3R, consistently achieves better performance than using only the original image pair as input (DUSt3R - Pair) across all datasets, achieving lower rotation and translation errors.
This also applies to MASt3R. While MASt3R excels with overlapping pairs via feature matching, it struggles with non-overlapping ones due to unreliable correspondences. Our approach maintains robustness, outperforming MASt3R on outward-facing datasets and matching its performance on center-facing datasets. For detailed MASt3R results, please refer to the supplementary material.
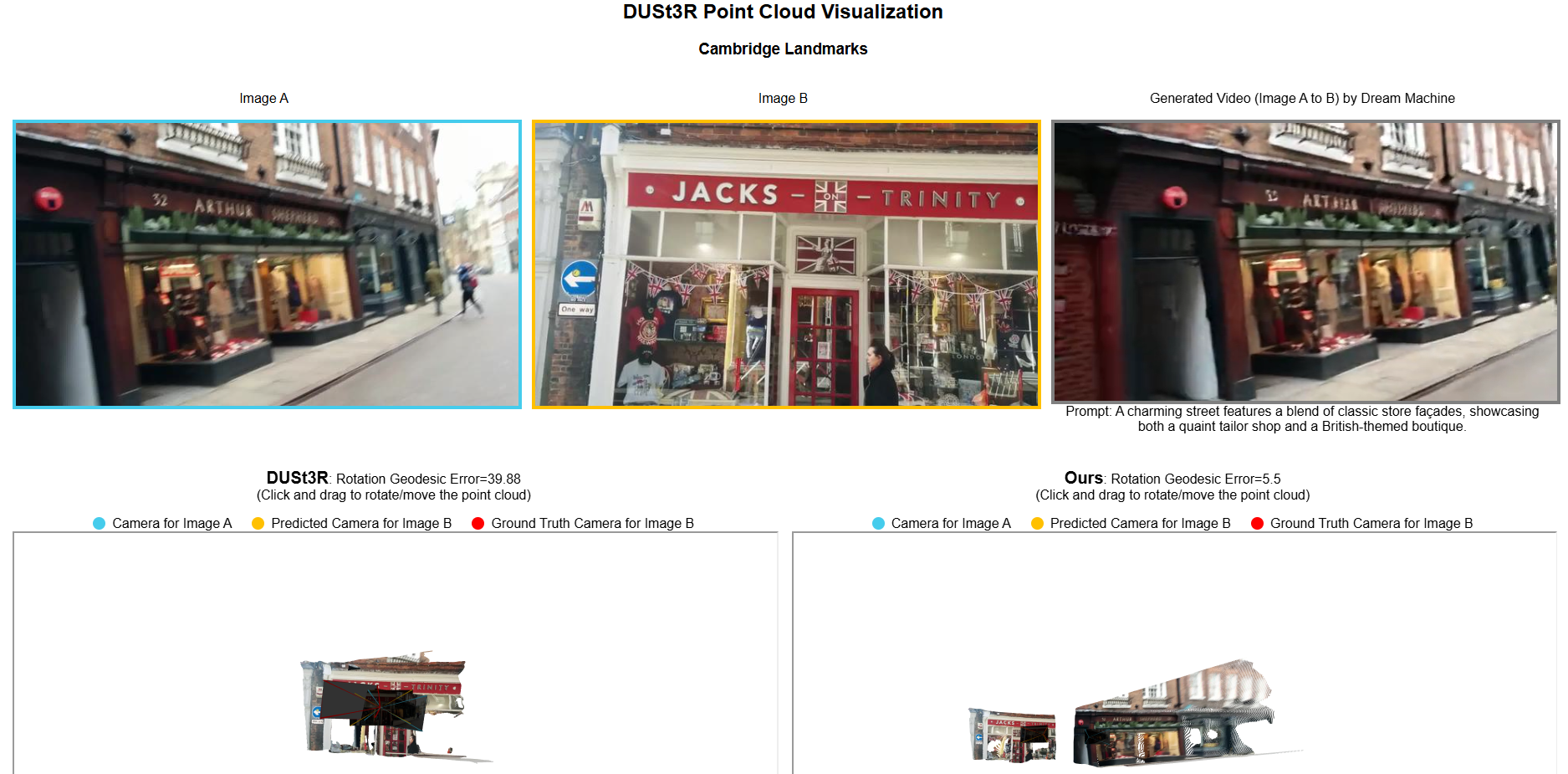
Qualitative Results
Check out the webpages for DUSt3R interactive point clouds and more examples on four datasets.
Acknowledgements
We would like to thank Keunhong Park, Matthew Levine, and Aleksander Hołynski for their feedback and suggestions.BibTeX
@inproceedings{InterPose,
title = {Can Generative Video Models Help Pose Estimation?},
author = {Cai, Ruojin and Zhang, Jason Y and Henzler, Philipp and Li, Zhengqi and Snavely, Noah and Martin-Brualla,
Ricardo},
booktitle = {CVPR},
year = {2025},
}